How to seed to a WholesaleBackup Server
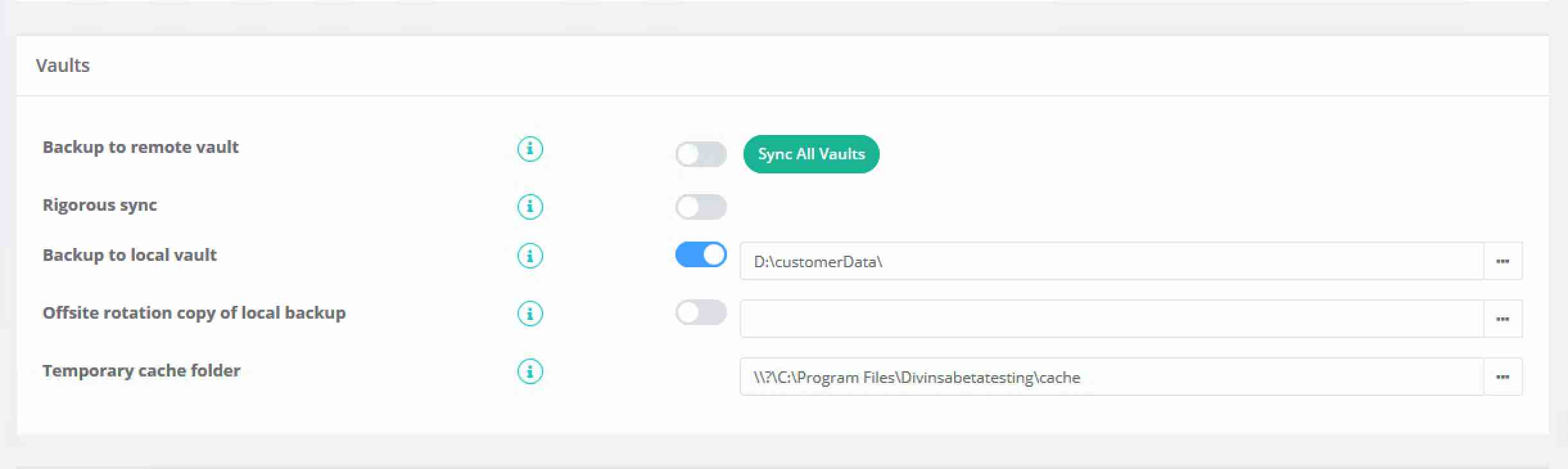
1. In the Backup > Settings tab set the client to backup to a local vault only, which can be a USB drive or a UNC path.
2. Start the backup
3. Wait for the backup to finish.
4. On the backup client, when you come to pick up the local vault, make sure to re-enable remote backups, and either keep making local backups or remove the local backup from the backup settings tab. Also, turn off the "Rigorous sync" option on the Backup > Settings page; when this setting is on, the backup client will verify if all the data is in the remote vault, and if you have not finished the seeding process, it will think that data is missing and try to back it up again.
5. Go into the backup client's install folder, make a copy of 'vault0000.db', and rename the copy to the new name of 'vault0105.db'.
Caution: This step needs to be done prior to re-enabling the backup client. The backup software uses the 'vault0000.db' to keep track of the data in the local vault, while the 'vault0105.db' keeps track of the data in the remote vault. Without this copy/paste, the backup client will not know the data has been seeded to the remote vault.
6. Copy the folder that was chosen in step 1 onto your backup server. It will have a number of subfolders (including vault, meta, settings, logs).
Copy the entire folder structure, including all subfolders, to the server, where the account is set up for that computer, the default location is generally '\userdata' of the installation folder.
e.g) C:\Program Files\WholesaleBackup\userdata\Divinsabetatesting\acct_name
Once all of the files are uploaded from your portable drive under the userdata folder on your server, when the next backup occurs, it should start performing incremental backups.
Copy the entire contents of this folder to you WSBU server, which for this example is saved to E:\. On E:\ you will see a matching "\Divinsabetatesting\acct_name\" folder, which should be the target for the copy.
Caution: When you re-enable remote backups on clients, do not enable rigorous sync on the client until their local seed has been successfully copied to their remote vault. Enabling rigorous sync before all the data is in place will cause the client to try to regenerate and resend all the "missing" blocks.
You are done! The next time the computer backs up only the changes will be uploaded to the server!
Please see the following article for factors that affect performance and suggestions for optimizing: https://support.wholesalebackup.com/hc/en-us/articles/202092304